這個時代,萬事都離不開資料,無論你是不是相關技術職位,都需要了解分析資料和處理數據的基本原理。尤其經理人,更應該學習如何正確看待數據,才能做出正確的決策(data driven dicisions)。Underfitting 和 overfitting 是在建立模型時,因為考屢因素過少或是過多產生的兩種的兩種偏誤。

『模型』並不是專屬於科學家,機器學習專家。我們每天都在『建立模型』並以此了解我們周遭發生的事。我們要討論的是更廣義的 underfitting 和 overfitting,了解這些錯誤的成因,知道如何避免,才能讓『資料』發揮最大的作用。
Underfitting 可以翻譯為『欠擬合』,其實是生活中也很常見的偏誤。 Underfitting 的問題在於考慮的參數太少,使用的模型太過簡單,或是誤用線性的關係。如果只用『腳的數量』來判斷一隻動物是否為『天鵝』,就是 underfitting 的一種極端例子。
考慮因素太少
Underfitting 的一種是考慮的因素(參數)過少,上面天鵝的例子可以算是一個。如果咖啡店要研究客戶分群,卻只看每一單的總金額,可能就沒辦法區分『買咖啡跟早餐的上班族』跟『吃點心下午茶』的兩種人群。(更好的方法,是可以用『咖啡消費』,『點心消費』,『外帶與否』,『結帳時間』等等作為分群。如果資料允許,也可以加入客戶方面的特徵。根據資料與常理判斷,再將模型適度簡化。)
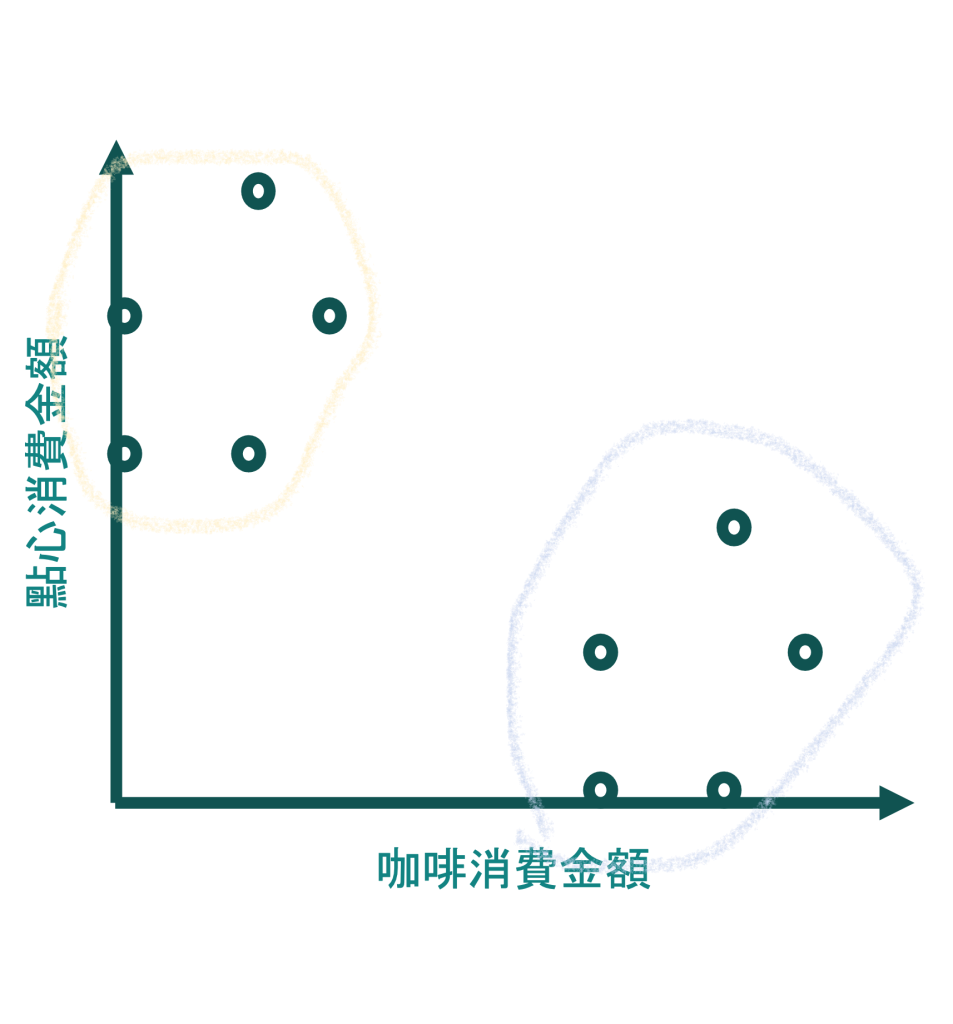
很多辛普森悖論(Simpson’s paradox)的例子也可以歸類於 underfitting。例如考量大學申請錄取率,只加入『性別』這個因素,而沒有考慮『申請的學院』。
模型太過簡單、誤用線性
在數學上,單一的變因可以與多個參數相關,越複雜的反應需要越多『參數』來描述。
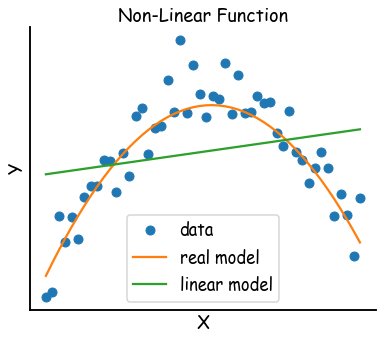
有些變因的影響力是 U 形或倒 U 形(例如室內溫度和舒適度的關係),有些則是有『飽和』現象(例如研討會提供點心的總量和消耗掉的點心量)。太過簡單的模型就沒有辦法正確描述這些不簡單的關係。

有些參數雖然看起來是數字,卻不適合當作線性的量化處理。
例如年齡:兩個三十歲的人加起來不會等於一個六十歲的人。兩個有一年經驗的工程師無法等同一個兩年經驗的工程師。另外,有些數值如果要做線性回歸分析的話最好經過轉換(transformation),例如取對數、根號,除了某些領域有約定俗成外,大部分情況也可以用『殘差分析』(redidual analysis)來鑑別。
過與不及都是問題
在探索式分析(EDA)階段,不太需要過於擔心 underfitting 的問題,但是要進一步驗證推論時,就要加入其他方法,或是等待更多資料進來。例如新建立的業務,只有 10 個客戶時,雖然可以探討『客戶性別』、『年齡』、『居住地』等等非常多因素與消費金額的關係,但是因為資料太少基本上無法構成結論。
到了統計分析,預測時就要注意,有時候模型表現不好是資料量的問題。所謂的參數過多過少,模型是否過於簡單,都要建立在資料量上。資料越多參數就可以越多。反之,資料不足時,參數過多又會有 overfitting 的問題(另外一篇討論),這種狀況就應該屈就於較簡單的模型。

Underfitting 與誤用線性關係 有 “ 5 則迴響 ”